
asr系统,语音识别技术的革命性突破
时间:2024-11-17 来源:网络 人气:
ASR系统:语音识别技术的革命性突破
一、ASR系统的基本原理
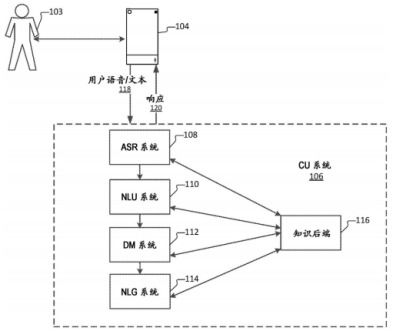
ASR系统是将人类的语音信号转换为计算机可处理的文本信息的技术。其基本原理主要包括以下几个步骤:
1. 语音信号采集
首先,ASR系统需要采集语音信号。这可以通过麦克风等设备实现,将声音转换为电信号。
2. 语音预处理
采集到的语音信号通常包含噪声、回声等干扰因素,需要进行预处理。预处理包括去噪、静音检测、分帧等操作,以提高后续处理的准确性。
3. 语音特征提取
预处理后的语音信号需要提取特征,以便后续的识别过程。常用的语音特征包括梅尔频率倒谱系数(MFCC)、线性预测编码(LPC)等。
4. 语音识别
提取到的语音特征将被输入到识别模型中进行识别。识别模型可以是隐马尔可夫模型(HMM)、深度神经网络(DNN)等。
5. 结果输出
识别模型输出识别结果,即文本信息。这些信息可以用于进一步的应用,如语音合成、文本搜索等。
二、ASR系统的应用领域
ASR系统在各个领域都有广泛的应用,以下列举几个典型应用场景:
1. 智能语音助手
智能语音助手如Siri、小爱同学等,通过ASR系统实现语音输入,为用户提供便捷的语音交互体验。
2. 在线客服
在线客服系统利用ASR系统实现语音识别,提高客服效率,降低人力成本。
3. 智能家居
智能家居设备如智能音箱、智能电视等,通过ASR系统实现语音控制,为用户提供便捷的生活体验。
4. 自动驾驶
自动驾驶汽车需要ASR系统实现语音输入,以便驾驶员与车辆进行交互。
5. 医疗健康
医疗健康领域,ASR系统可以用于语音病历记录、语音助手等应用,提高医疗效率。
三、ASR系统的发展趋势
1. 深度学习技术的应用
深度学习技术在语音识别领域取得了显著成果,未来ASR系统将更多地采用深度学习模型,提高识别准确率和鲁棒性。
2. 多语言、多方言支持
随着全球化的推进,ASR系统将支持更多语言和方言,满足不同地区用户的需求。
3. 个性化定制
ASR系统将根据用户习惯和需求进行个性化定制,提供更加贴心的服务。
4. 跨领域融合
ASR系统将与其他领域技术如自然语言处理、计算机视觉等相结合,实现更加智能的应用。

教程资讯
教程资讯排行









