
分布式文件系统特点,分布式文件系统特点解析
时间:2024-12-22 来源:网络 人气:
分布式文件系统特点解析
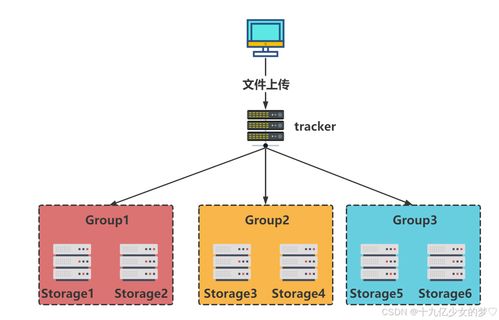
随着大数据时代的到来,分布式文件系统(Distributed File System,DFS)在数据存储领域扮演着越来越重要的角色。本文将深入解析分布式文件系统的特点,帮助读者更好地理解这一技术。
一、高可扩展性

分布式文件系统具有极高的可扩展性,这是其最显著的特点之一。通过增加节点,分布式文件系统可以水平扩展,支持存储PB级别的数据。这种扩展性使得分布式文件系统能够满足不断增长的数据存储需求。
二、高容错性

分布式文件系统采用数据冗余机制,将数据块存储在多个节点上,从而提高了系统的容错性。即使某个节点发生故障,系统也能从其他节点恢复数据,保证数据的安全性和可靠性。
三、高吞吐量

分布式文件系统通过并行处理数据,实现了高吞吐量。在处理大规模数据集时,分布式文件系统可以充分利用集群的威力,提供高效的读写性能。
四、数据一致性

分布式文件系统采用一致性模型,确保数据的一致性。在数据更新过程中,系统会保证所有节点上的数据保持一致,避免出现数据不一致的情况。
五、易于管理

分布式文件系统采用集中式管理方式,简化了数据存储和管理过程。管理员可以通过统一的界面进行数据备份、恢复、监控等操作,降低了运维成本。
六、跨平台兼容性

分布式文件系统通常采用跨平台技术,支持多种操作系统和硬件平台。这使得分布式文件系统可以方便地与其他系统进行集成,提高数据存储的灵活性。
七、支持大文件存储

分布式文件系统专门为存储大文件而设计,可以轻松处理TB、PB级别的数据。这使得分布式文件系统成为大数据存储的理想选择。
八、支持流式访问

分布式文件系统放宽了POSIX的要求,可以以流的形式访问文件系统中的数据。这使得分布式文件系统在处理大规模数据流时具有更高的效率。
分布式文件系统凭借其高可扩展性、高容错性、高吞吐量、数据一致性、易于管理、跨平台兼容性、支持大文件存储和流式访问等特点,成为大数据存储领域的首选技术。随着大数据时代的不断发展,分布式文件系统将在数据存储领域发挥越来越重要的作用。

教程资讯
教程资讯排行









