
分布式网络爬虫系统,分布式网络爬虫系统的设计与实现
时间:2024-12-16 来源:网络 人气:
分布式网络爬虫系统的设计与实现
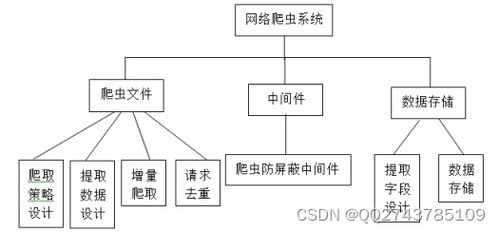
一、系统架构

分布式网络爬虫系统通常采用分层架构,主要包括以下几个层次:
数据层:负责存储和管理爬取到的数据,通常采用分布式数据库或文件系统,如Hadoop的HDFS。
爬虫层:负责从互联网上抓取数据,包括URL队列管理、页面解析、数据提取等模块。
调度层:负责分配爬虫任务,协调各个爬虫节点的工作,确保系统的高效运行。
监控层:负责监控系统运行状态,包括爬虫节点状态、数据存储状态等,及时发现并解决问题。
二、关键技术

分布式网络爬虫系统涉及多个关键技术,以下列举几个重要技术:
分布式存储:采用分布式数据库或文件系统,如Hadoop的HDFS,实现海量数据的存储和管理。
分布式爬虫框架:如Scrapy、PySpider等,提供分布式爬虫的框架和工具,简化爬虫开发过程。
分布式调度:采用分布式调度算法,如MapReduce,实现爬虫任务的合理分配和高效执行。
反反爬虫策略:针对目标网站的反爬机制,采用代理IP、用户代理伪装、请求间隔控制等技术,提高爬虫成功率。
数据清洗与处理:对爬取到的数据进行清洗、去重、格式转换等操作,提高数据质量。
三、系统实现

以下以Scrapy为例,介绍分布式网络爬虫系统的实现过程:
搭建分布式爬虫环境:安装Scrapy、Redis、Python等依赖库,配置分布式爬虫框架。
编写爬虫代码:根据目标网站的特点,编写爬虫代码,实现URL队列管理、页面解析、数据提取等功能。
配置分布式调度:使用Scrapy-Redis等插件,将爬虫任务分配到多个爬虫节点,实现分布式爬取。
数据存储与处理:将爬取到的数据存储到分布式数据库或文件系统,并进行数据清洗和处理。
监控系统运行状态:使用Scrapy-Redis等插件,实时监控爬虫节点状态、数据存储状态等,确保系统稳定运行。
四、实际应用

分布式网络爬虫系统在多个领域具有广泛的应用,以下列举几个典型应用场景:
搜索引擎:通过分布式爬虫系统,从互联网上抓取海量网页数据,构建搜索引擎索引库。
数据挖掘:利用分布式爬虫系统,从互联网上抓取特定领域的海量数据,进行数据挖掘和分析。
舆情监测:通过分布式爬虫系统,实时抓取互联网上的舆情信息,为政府、企业等提供决策支持。
商业应用:利用分布式爬虫系统,抓取竞争对手的网站数据,进行市场分析和竞争情报收集。
分布式网络爬虫系统在处理大规模数据时具有显著优势,能够提高爬虫效率、扩展性和稳定性。本文介绍了分布式网络爬虫系统的设计与实现,包括系统架构、关键技术以及实际应用。随着技术的不断发展,分布式网络爬虫系统将在更多领域发挥重要作用。

教程资讯
教程资讯排行









