
分布式系统数据一致性
时间:2024-12-12 来源:网络 人气:
分布式系统数据一致性的挑战与解决方案
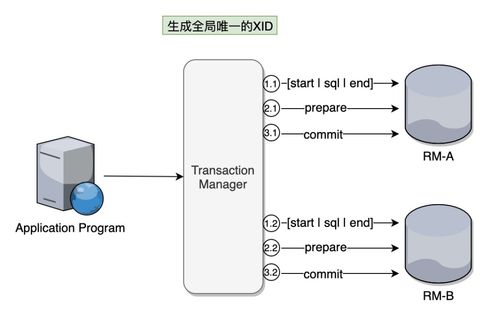
一、分布式系统数据一致性的挑战

分布式系统数据一致性的挑战主要来源于以下几个方面:
1. 网络延迟和分区容忍性
在分布式系统中,节点之间通过网络进行通信,网络延迟和分区容忍性是影响数据一致性的重要因素。网络延迟可能导致数据同步延迟,而分区容忍性则要求系统能够在部分节点失效的情况下保持正常运行。
2. 数据复制和分区
为了提高数据的可用性和容错性,分布式系统通常会将数据复制到多个节点上。数据复制和分区策略的选择不当,可能导致数据不一致的问题。
3. 事务处理
在分布式系统中,事务处理需要保证原子性、一致性、隔离性和持久性(ACID属性)。在分布式环境下,事务的执行过程复杂,难以保证ACID属性。
二、分布式系统数据一致性的解决方案
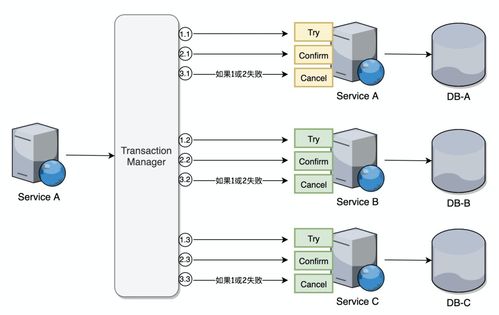
1. 强一致性模型
强一致性模型要求所有节点上的数据在任何时刻都是一致的。常见的强一致性模型包括Paxos算法、Raft算法等。这些算法能够保证在分布式系统中实现强一致性,但可能会牺牲性能。
2. 最终一致性模型
最终一致性模型允许系统在一段时间内存在数据不一致的情况,但最终会达到一致。这种模型适用于对实时性要求不高的场景,如分布式缓存、消息队列等。
3. 分布式事务处理
分布式事务处理需要保证事务的ACID属性。常见的分布式事务处理方案包括两阶段提交(2PC)、三阶段提交(3PC)等。这些方案能够保证分布式事务的一致性,但可能会增加系统复杂性和性能开销。
4. 分布式锁
分布式锁是一种用于协调分布式系统并保证数据一致性的机制。通过分布式锁,可以确保同一时刻只有一个进程或线程可以修改共享资源,从而避免数据竞争和不一致的问题。
分布式系统数据一致性是一个复杂且关键的问题。在设计和实现分布式系统时,需要充分考虑数据一致性的挑战,并选择合适的解决方案。本文介绍了分布式系统数据一致性的挑战和解决方案,希望能为读者提供一定的参考。

教程资讯
教程资讯排行









