
分布式系统id,湰鐖辨儏鐗噈v
时间:2024-12-01 来源:网络 人气:
分布式系统中的唯一ID生成策略
在分布式系统中,唯一ID的生成是一个关键问题。随着分布式应用的普及,如何确保每个节点生成的ID全局唯一,同时保证高性能和高可用性,成为开发者和架构师们关注的焦点。
一、分布式ID生成的重要性
全局唯一性:确保不同节点生成的ID不会重复,避免数据冲突。
高性能:快速生成ID,减少系统延迟,提高系统吞吐量。
高可用性:在系统高并发情况下,保证ID生成服务的稳定性。
易于管理:方便对ID进行排序、查询等操作。
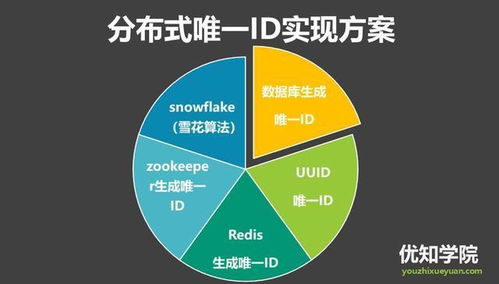
二、常见的分布式ID生成方案
1. UUID
UUID(Universally Unique Identifier)是一种基于随机数的唯一标识符。其优点是简单易用,但缺点是长度较长(128位),不利于数据库索引优化,且无序。
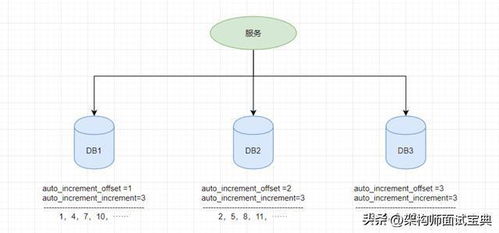
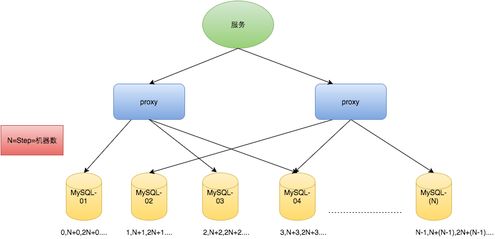
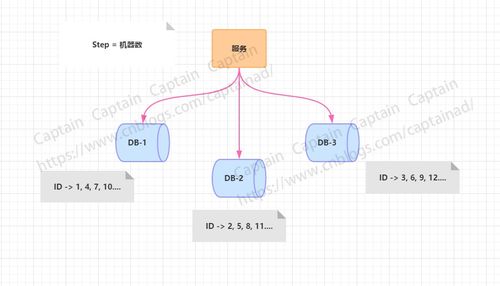
2. 数据库自增ID
数据库自增ID是一种常见的ID生成方式,但缺点是并发性能不高,且容易成为性能瓶颈和单点故障。
3. Redis自增
Redis自增ID可以解决数据库自增ID的缺点,但Redis负载过高时,ID生成速度会受到影响。
4. 雪花算法
雪花算法(Snowflake)是一种基于时间戳、机器标识和序列号的ID生成算法。其优点是全局唯一、高性能、有序,且易于实现。
三、雪花算法原理及实现
雪花算法是一种基于时间戳、机器标识和序列号的ID生成算法。其原理如下:
0 - 41位时间戳:表示毫秒级时间戳,可以表示69年的时间。
10位机器ID:用于标识不同的机器,支持最多1024个节点。
12位序列号:在同一毫秒内生成的ID序列号,支持每毫秒生成4096个ID。
以下是一个简单的雪花算法实现示例(Java):
```java
public class SnowflakeIdGenerator {
private long workerId;
private long datacenterId;
private long sequence = 0L;
private long twepoch = 1288834974657L;
private long workerIdBits = 5L;
private long datacenterIdBits = 5L;
private long maxWorkerId = -1L ^ (-1L maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format(
相关推荐


教程资讯
教程资讯排行









