
关系数据库系统中使用的数据结构是,关系数据库系统中的数据结构概述
时间:2024-11-28 来源:网络 人气:
关系数据库系统中的数据结构概述
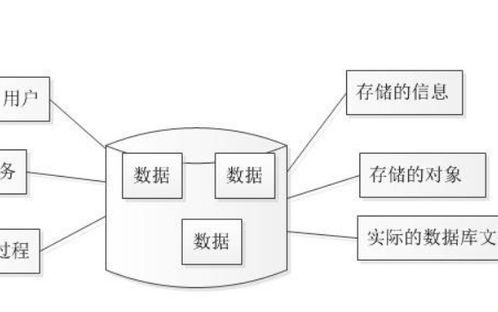
关系数据库系统(RDBMS)是现代数据库技术的基础,它使用一种称为关系模型的数据结构来组织和存储数据。关系模型由E.F.Codd在1970年提出,自那时起,它已经成为数据库设计和管理的主流方法。本文将探讨关系数据库系统中使用的主要数据结构及其特点。
关系模型的基本概念

关系模型的核心是“关系”,它是一个二维表,由行和列组成。每一行称为一个“元组”,每一列称为一个“属性”。关系模型中的数据通过这些元组和属性来组织,每个元组代表一个实体,每个属性代表实体的一个特征。
关系数据结构的特点
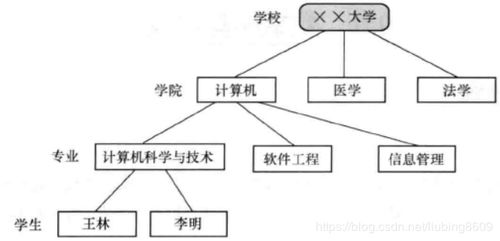
关系数据结构具有以下特点:
结构化:数据以表格形式组织,易于理解和操作。
完整性:通过定义数据约束(如主键、外键、唯一性约束等)来保证数据的准确性和一致性。
独立性:数据的逻辑结构和物理存储结构分离,便于数据管理和维护。
可扩展性:易于添加新的属性和元组,适应数据增长的需求。
关系数据库中的主要数据结构
关系数据库中的主要数据结构包括以下几种:
1. 关系(Table)
关系是关系数据库中最基本的数据结构,它由行和列组成。行代表实体,列代表实体的属性。例如,一个学生关系可能包含学号、姓名、性别、年龄等属性。
2. 元组(Tuple)
元组是关系中的一行,代表一个实体。每个元组包含多个属性值,这些属性值构成了实体的完整信息。
3. 属性(Attribute)
属性是关系中的一列,代表实体的一个特征。每个属性都有一个数据类型,用于定义该属性可以存储的数据类型。
4. 主键(Primary Key)
主键是关系中的一个属性或属性组合,用于唯一标识关系中的每个元组。一个关系只能有一个主键。
5. 外键(Foreign Key)
外键是关系中的一个属性或属性组合,它在一个关系中引用另一个关系的主键。外键用于建立关系之间的联系,实现数据的完整性。
关系数据库的查询语言
关系数据库使用查询语言(如SQL)来操作数据。SQL语言提供了丰富的查询功能,包括选择、投影、连接、更新和删除等操作。
关系数据库的性能优化
索引:通过创建索引来加速查询操作。
查询优化:优化查询语句,减少查询时间。
分区:将大型表分割成多个小表,提高查询效率。
缓存:缓存常用数据,减少磁盘I/O操作。
关系数据库系统中的数据结构是数据库设计和管理的基础。通过使用关系模型,我们可以有效地组织和存储数据,保证数据的完整性、独立性和可扩展性。了解关系数据库中的数据结构对于数据库开发者和管理员来说至关重要。
相关推荐


教程资讯
教程资讯排行









