
分布式大数据系统,架构、技术与挑战解析
时间:2025-04-20 来源:网络 人气:
亲爱的读者们,你是否曾想过,在浩瀚的数据海洋中,如何才能找到属于自己的宝藏?今天,就让我带你一起探索分布式大数据系统的奇妙世界,看看它是如何让海量数据变得触手可及的!
数据海洋中的航标:分布式大数据系统
想象你站在一个巨大的图书馆前,里面藏书无数,而你只需要找到一本特定的书。这就像我们在处理海量数据时面临的挑战。传统的数据库已经无法满足我们对数据存储和处理的巨大需求,这时,分布式大数据系统就像一位智慧的大厨,将数据烹饪成美味佳肴。
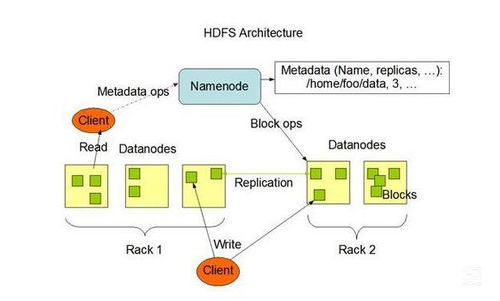
存储与计算的盛宴:Hadoop的华丽舞步
Hadoop,这位大数据领域的明星,由Apache基金会开发,旨在解决海量数据的存储和处理问题。它就像一位魔法师,将数据分散存储在集群中的多台服务器上,并通过分布式计算的方式进行高效处理。
Hadoop的核心是HDFS(Hadoop Distributed File System),它将数据切分为多个块,并将这些块分散存储在集群中的多台服务器上。这种分布式存储的方式保证了数据的冗余性和可靠性,同时也实现了高效的数据访问。
而Hadoop的计算框架MapReduce,则采用了“计算移动到数据”的思想。通过将任务分解成多个子任务,并在集群中的多台服务器上并行执行,MapReduce可以高效地处理大规模数据集。
Spark:大数据的加速引擎
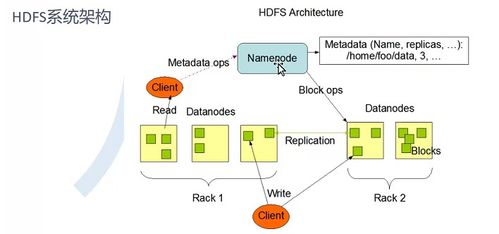
随着大数据时代的到来,传统的MapReduce在处理速度上逐渐显得力不从心。这时,Spark这位加速引擎应运而生。它基于内存计算,数据处理速度快如闪电。
Spark不仅继承了Hadoop的分布式存储和计算能力,还提供了丰富的API,使得开发者可以轻松地构建大数据应用。Spark的生态圈也非常丰富,包括Spark SQL、Spark Streaming等,为大数据处理提供了全方位的支持。
大数据生态圈:周边技术的华丽配饰
有了存储和计算框架,周边技术就像一件华丽的配饰,为大数据系统增色不少。
YARN(Yet Another Resource Negotiator)解决了多租户资源调度的难题,Flume解决了数据传输的难题,Sqoop解决了分布式存储数据与传统DB数据之间的转换,Oozie解决了大数据计算任务的调度,Kafka提供了发布订阅机制的消息队列,Zookeeper可以帮助用户完成主备的选举,Hive在HDFS的基础上提供了数仓的功能,HBase则基于HDFS实现列式数据库……
这些周边技术就像一位位助手,为大数据系统提供全方位的支持。
分布式系统:挑战与机遇并存
分布式系统虽然强大,但也面临着诸多挑战。分布式并发操作、数据一致性、故障处理等问题都需要我们认真面对。
挑战与机遇并存。分布式系统的高可靠性、可扩展性和可维护性,使得它成为大数据时代不可或缺的基石。
:分布式大数据系统,开启数据新时代
分布式大数据系统就像一位智慧的大厨,将海量数据烹饪成美味佳肴。它不仅改变了我们对数据的认知,更开启了数据新时代的大门。
在这个新时代,让我们携手分布式大数据系统,共同探索数据世界的奥秘,开启无限可能!

教程资讯
教程资讯排行









